

Snowflake vs Databricks, the birth of unlimited and decoupled data scaling in the cloud, and Snowflake's outlook
Snowflake vs Databricks, the birth of unlimited and decoupled data scaling in the cloud, and Snowflake's outlook
An overview of the space

The birth of unlimited and decoupled data scaling in the cloud
Old-school data management systems turned out to be a nightmare at handling the rise of the internet. Whereas these SQL-based systems provide attractive consistency guarantees coupled with a dazzling capability at steering complex queries, these features came with one huge drawback, the system doesn’t scale. Or at least, only vertically. This means that when your organization grew in size and you had to handle more data, you basically had to buy a bigger server with more memory and more CPUs. With the rise of the internet and the accompanying explosion of data this turned out to be a very unsuited design.
There was a clear need to start scaling horizontally, so that you could simply store your data over more servers. Enter NoSQL databases — such as MongoDB, Cassandra and AWS DynamoDB — which provide these characteristics. However, the drawback here is that NoSQL databases are extremely poor at complex queries, as you organize your data based on how you run your business. So it’s easy to get the data for example which orders ‘customer Bob’ made, but any sophisticated query beyond that turns out to be a problem.
This is where data warehouses come in. Via data pipelines, the data is transferred from the database world into the data warehouse world, so that you can run analytics on it. This data is then transferred to nice dashboards so that managers can understand what’s going on inside the business.
In the old world, these data warehouses were also SQL-based and ran on a big vertical server. The main reason for this separation was to take workload of the main server. Remember, there was one server doing all the work and so you wanted to help it as much as possible from any burden. So the data warehousing you would run on a separate server, and you would also make slave copies of the original server to handle reads for example. Whenever the business needed to make a database query, the slave servers would handle these, with the master server taking care of all the writes.
In the new data warehousing world, obviously there was a need for horizontal scaling as well. Over the last two decades, we have seen three generations of solutions here. The first was Hadoop, which allowed for horizontal data scaling in on-premise datacenters. However, Hadoop is a difficult system to manage with a number of other downsides, making a service-based cloud solution a much more attractive option. The first of these was AWS Redshift, a much more customer friendly platform running on the AWS cloud, the pioneering public hyperscaler at the time.
The problem with Redshift’s architecture however is that compute and storage are coupled together. So as your data grows in size, you have to commission more servers, where you have to pay for the compute resources these provide. However, you might only be running analytics for a few hours each day. This basically means that for all the other hours of the day, you’re paying for compute resources which you’re not using.
This is where the the third generation of horizontally scalable data warehouses enter the scene, which Snowflake pioneered. Not only does Snowflake provide unlimited data scaling in the cloud, but it does so in a decoupled manner. This means that your storage and compute resources are fully separated. The clever trick which the Snowflake team leveraged is that they would not store data on rented servers in the cloud, but make use of the extremely prevalent and cheap object stores which the public clouds provide. Compute resources would only spin up when the user is running analytics, saving the customer from having to pay for unused resources. Vice versa, during intervals where the customer is not using his data warehouse, the data would just sit and rest in the object stores (SSDs), with compute resources having been fully wound down.
Snowflake vs Databricks
Snowflake and Databricks were initially founded to address very different purposes. Whereas Snowflake’s goal was to provide a clever and fully scalable data warehouse in the cloud, where you could run traditional SQL queries and business analytics on, the goal of Databricks was to make it straightforward to run scalable data science clusters in the cloud. So with Databricks, you could easily spin up a Spark cluster to process your data, with the coding written in a handy notebook in one of your favorite data science languages such as Python or Scala. As the platform is running in the cloud, these notebooks could easily be shared with other data scientists or the community to collaborate on projects.
These two different workloads — business SQL vs data science — are still each respective company’s stronghold. However, over the previous years, both companies have been building out their capabilities with the goal of establishing a complete data platform in the cloud, with data warehousing, data processing, and data streaming capabilities.
Snowflake’s answer to Databricks is SnowPark, which similarly to the pioneer offers the ability to process data from notebooks written in popular programming languages. Under the hood, Databricks runs its processes on Spark clusters, or Photon clusters actually these days, a C++ optimized version of Spark. Whereas Snowflake uses it own compute engines, which will be written in C++ as well. Spark was originally written in Scala which is somewhat slower, so rewriting the code in C++ will provide obvious performance gains. And I guess at some point the code will be rewritten in Rust, the new and much cooler C++, as the latter is basically a major pain to work with, especially if you want to import a library. Vice versa, Databricks has been building out its data storage solution by leveraging public clouds’ object stores. You can now run traditional SQL within Databricks ‘Data Lakehouse’.
As such, both platforms are now well capable to store both structured and unstructured data. And both have been implementing ACID compliance, meaning that data transactions will only be enforced in a consistent manner. Both also have a similar pricing model, where you only pay for compute when virtual machines are running. Reading through the Databricks documentation, the platform seems to have become extremely comprehensive and my impression is that it should be well capable to start competing effectively with Snowflake. Snowflake is successfully plowing ahead as well however, as SnowPark is estimated to become a $100 million dollar revenue business this year. Which indicates clearly that the platform is being successful at attracting data science workloads.
An overview of the Databricks platform is illustrated below. The difference with Snowflake however is that the storage layer is still separated. So a customer can individually manage his storage in his hyperscaler account whereas with Snowflake this is usually still vertically integrated, i.e. a so-called ‘walled garden’. The reason for this difference is that Databricks make use of an open source table format called Delta Tables, making it easy for the customer to process data elsewhere, not necessarily only over the Databricks platform.

Snowflake is now going down the same route, by allowing customers to store their data outside of the platform in Apache Iceberg tables. Iceberg is similarly to Delta an open source table format, providing customers with the alternative to utilize their data in other systems. Going forward, a customer could make use of their Iceberg data and process it on Databricks clusters. While this erodes Snowflake’s moat, I suspect that introducing this feature will still be a net positive for the company long term, as being a closed system made some clients reluctant to upload their data into Snowflake.
This is Snowflake’s CFO discussing their competition with Databricks at Goldman:
“First of all, I think Databricks is a very good company, I'm not going to say anything bad about them. What they do very well is in data science. We never see their SQL product and they undercut the pricing on that to try to win stuff, but we just don't see it. They still do a lot of ETL (extract, transform & load) and they coexist in so many of our accounts as we've brought them in. I know in your bank, they use both Snowflake and Databricks, and you go talk to most of our accounts, and they really see them as very different products. Where we compete with Databricks is on a workload-by-workload basis. It's a massive market we're playing in and it's not a winner takes all. There's going to be many winners.”
We got some further details at the recent Morgan Stanley conference, from the CFO again:
“It's been very consistent since day one, when we are going in to migrate a customer from on-prem Teradata or Hadoop, we're generally competing with Google, Azure and then AWS. We do see Databricks in many of our large accounts and by the way, we helped bring them in when we were kind of partnering with them. And they do very well in data science because they have a very good notebook that people like. But I will tell you, a lot of that growth in SnowPark has been at the cost of growth in Databricks within our accounts. And we are showing our customers that we are dramatically cheaper than them too.”
Snowflake has in the past discussed that they’re not only replacing a lot of on-premise Teradata and Hadoop solutions, but also other classic SQL data warehousing products such as Oracle, Microsoft and IBM, as well as first generation cloud data warehouses such as AWS Redshift.
Comparing results for 2023, Databricks grew faster percentage-wise although Snowflake still added more revenues dollar-wise:

So Snowflake is still the larger of the two, however, it’s clear that Databricks performance has been very strong and that the company has been growing into a serious competitor over time.
The hyperscalers fight back
Naturally the hyperscalers aren’t sitting still. AWS’ Redshift now also allows users to store their data in object storage, decoupling the data from compute resources, meanwhile Google’s BigQuery is still one of Snowflake’s strongest competitors. BigQuery is very expensive, as is the Google Cloud as a whole, which is a key factor I suspect why they’ve been lagging compared to the strong growth Azure has been generating.
Also Microsoft has been building up a data platform in their Azure cloud. On the illustration below you can see how this platform covers all the elements we discussed above. I.e. various types of data can be collected via pipelines and stored in a data lake, compute resources can connect to these object stores, and then users can run business analytics and machine learning from these resources:

Long term this could actually be the biggest threat to Snowflake, as the public clouds are both suppliers as well as competitors to Snowflake. So what they could do is make pricing more unattractive for Snowflake to host its platform on their respective clouds, while at the same time offer attractive pricing for their own data platforms to attract end users. Databricks could face the same problem, as do MongoDB, Confluent, Elastic etc, all companies who provide their software in the public cloud but where the hyperscalers themselves offer competing products. Although note that this hasn’t happened so far, Snowflake has been able to get better pricing actually as the cloud providers want Snowflake on their cloud.
When it comes to competition, it seems that currently both Azure and AWS are definitely behind. The three names which consistently get mentioned — and that also incumbent Teradata mentioned as their top three competitors — are Snowflake, Databricks and BigQuery.
To reduce potential competitive forces, Snowflake has been aiming to create a network effect around its platform so that companies can share their data with partnering companies in their supply chains. This is the CFO explaining this product at Goldman:
“Data sharing is a key differentiator for Snowflake, that is a great lead generator for us. And we really see that taking off in financial services, we're seeing a lot of our customers who are telling their data suppliers that they want them on Snowflake. It's a huge network effect. And a lot of people talk about data sharing, but we're really the only ones who do it where the data actually never moves, the custodian of that data always retains that data.”
To bring machine learning to the Snowflake platform, the company has also been investing to make it easy for customers to deploy data in customer apps with the acquisition of Streamlit. This library allows customers to write simple Python code to easily spin up apps which can visualize this data, and is now being built in into SnowPark. An example of an app created with Streamlit:

Before we continue with Snowflake, I’d like to give a brief shout-out to our friends at mybuyside.io. It’s a great platform for buy-side analysts and portfolio managers to exchange brief stock pitches, in less than 300 words. So if you’re active in money management, please check them out.
Snowflake’s outlook
Although Snowflake’s revenue growth has remained decent, percentage-wise we’ve been seeing a deceleration towards growth at just above 30% rates.

For the 2025 fiscal year we’re now entering, the company is guiding to only grow at a 22% rate, in combination with the gross margin also seeing some headwinds and falling back to 76%:
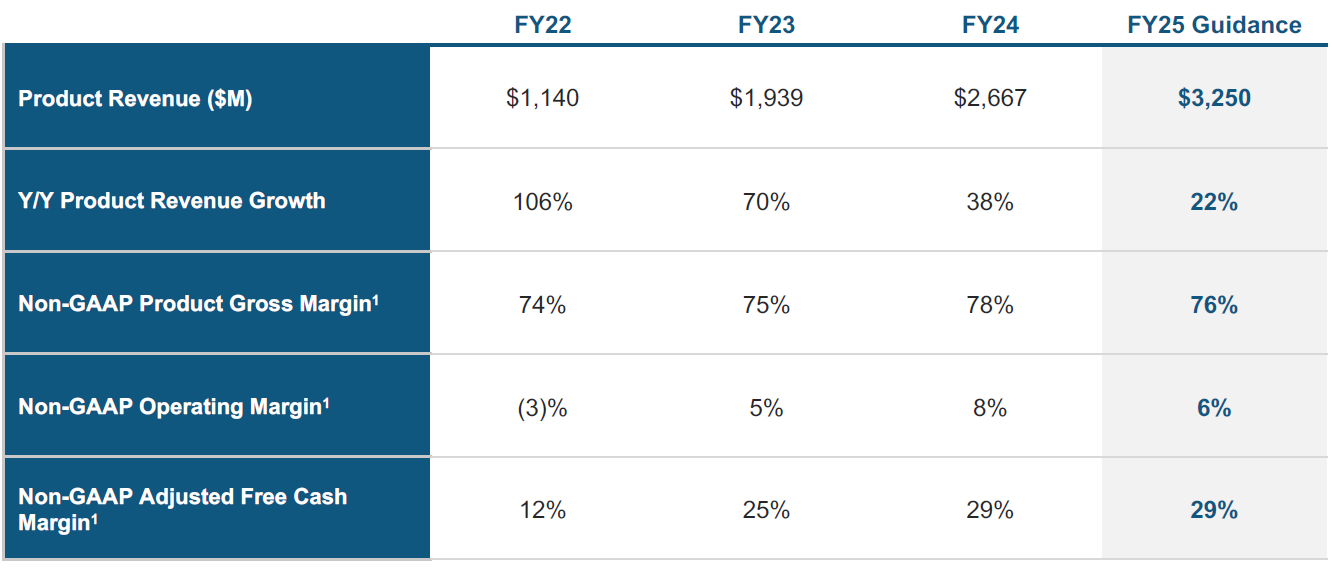
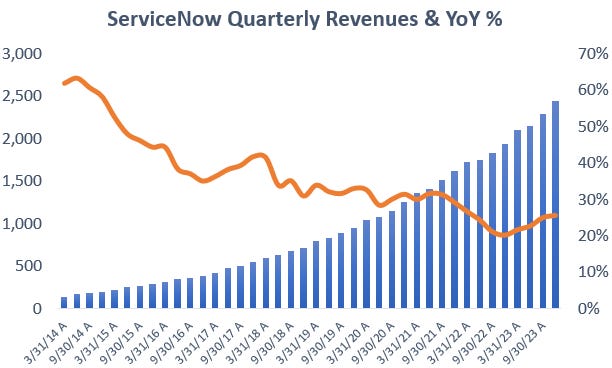
This has been a disappointment for the market as with the strength of Snowflake’s platform, it was expected that the company could sustain high growth rates for a long time to come. You can see that ServiceNow started at a similar quarterly revenue level around six years earlier than Snowflake, and managed to keep growing at a 30%-plus rate for more than seven years subsequently:
This is Chairman and outgoing CEO Frank Slootman discussing the headwinds Snowflake faced during 2023:
“The year began against an unsettled macroeconomic backdrop. We witnessed lackluster sentiment and customer hesitation due to a lack of visibility in their businesses. Customers preferred to wait and see versus leaning into longer-term contract expansions. This reversed in the second half of the year, and we started seeing larger multi-year commitments. Q4 was an exceptionally strong bookings quarter, we reported $5.2 billion of remaining performance obligations, representing accelerated year-on-year growth of 41%. Meanwhile, Snowflake has announced many new technologies that let customers mobilize AI. We also received FedRAMP High Authorization on the AWS GovCloud. This enables Snowflake to protect some of the federal government's most sensitive, unclassified data.”
Snowflake’s CFO subsequently issued their cautious outlook:
“Consumption trends have improved since the ending of last year, but have not returned to pre-FY '24 patterns. We have evolved our forecasting process to be more receptive to recent trends. For that reason, our guidance assumes similar customer behavior to fiscal 2024. We are forecasting increased revenue headwinds associated with product efficiency gains, tiered storage pricing and the expectation that some of our customers will leverage Iceberg Tables for their storage. We are not including potential revenue benefits from these initiatives in our forecast. These changes in our assumptions impact our long-term guidance. Internally, we continue to march towards $10 billion in product revenue. Externally, we will not manage expectations to our previous targets until we have more data.”
So somewhat of a mixed messaging. It seems that the company is trying to set conservative expectations, so that if headwinds continue to weigh on growth, the company can still meet the guidance whereas if the situation improves, the company can move into a beat and raise cycle.
The CFO did confirm at the recent Morgan Stanley conference that this guidance is indeed prudent:
“Consumption trends are good right now. But we have so many new products coming to GA (general availability) that we're not going to forecast those until we start seeing a history of consumption. So I do think there's, call it conservatism, I call it prudent guidance, and we'll take it one quarter at a time. The spending environment is actually pretty good with our customers. I just think a lot of the customers we have now that are ramping on Snowflake, are a lot more disciplined. More mature companies than a lot of the digitally native companies where they had these massive valuations and money being thrown at them that they just spent euphorically. The customers we're bringing on and ramping up today, big telcos and banks kind of stuff, have always been very cost-conscious, and they're going to do things at their pace.”
There are a number of indicators that growth should pick up from here. Firstly, remaining performance obligations (RPOs) were unusually strong, growing 40% year on year. You can see that this number had been stagnating over the previous quarters:
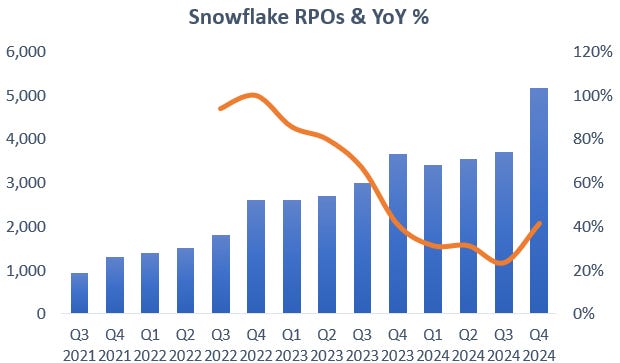
Note that RPOs are multi-year bookings, it is basically capacity clients are purchasing which can be consumed on the platform over a number of years. So it doesn’t necessarily mean that consumption and therefore revenues will pick up in the coming months, as clients might decide to shift workloads in 9 to 15 months from now. But it remains an indicator that clients are planning to increase resources on the Snowflake platform at a high rate over the medium term.
The company recently started breaking out how much of these RPOs we can expect to see come through in the next twelve months and we can see a clear sequential jump as well here, although the year-over-year growth rate remains at around 30%:

Management has also been talking about how they changed the incentive structure of their sales force with the expectation that this is going to accelerate revenue growth. Basically, compensation is now linked with customers’ platform consumption as opposed to bookings. The CFO going into this topic:
“One of the reasons why we switched to paying reps more on consumption is because we want reps to be driving revenue more rather than bookings. I've been at the company now almost 5 years. One of the first things when I sat down with Frank and we're thinking about what we need to do on the go-to-market, the change was that the company previously used to just pay reps on bookings. They just sold a one-year deal and customers get an unlimited rollover. So you had early on a lot of customers that were oversold because customers didn't care and reps got a big commission all upfront. And one of the first things we said is we need to change that. We really only want customers to buy what they think they're going to consume. I was like “we'll get a customer to buy a three year contract, and if they renew for an amount equal to or greater, we'll let them roll over any unused stuff”. So we started four years ago this transition, and I told the team “eventually, we're going to get to 100% commission on consumption”.
Last year, what happened, we had a small spiff for landing new customers. Reps had a growth quota that could come from a new customer, that could come from an upsell. And reps gravitated towards just upsells because it was easier than spending the time going through the security review and getting a new customer. So our comp plan this year is 35% of our reps, their only job is to land new customers, get that initial contract. And then 55% of the reps are just on revenue only. Their job is to be at the customer, walking the halls, finding new workloads to drive more revenue. And then 10% are what we call hybrid, that have a mix of new customers and some small number of existing customers.”
As a reminder, Snowflake books revenues as customers consume on the platform, i.e. run workloads and store data. This decreases RPOs and then gets taken through the P&L in the form of revenues. However, the bulk of this cash is actually collected upfront, as clients are billed annually in advance. So if a customer consumes more capacity than was agreed in the contract, he will have to top up payments. If less is consumed, it sounds like going forward Snowflake will only allow the remaining capacity to be rolled over if the customer renews the contract for an equal or larger amount, which means having to make another payment. This is why Snowflake’s cash generation is so strong, payments are collected well in advance. And the other attraction from this business model is that revenues are linked with the growth in data and in data analysis workloads. So as also more machine learning is happening on the platform, this compute gets directly translated into revenues.
A second reason why there should be optimism for growth to pick up, is that the company isn’t baking in upside from their new product launches into their guidance. The only exception is SnowPark, which is expected to contribute 3% to revenues. SnowPark is definitely a great product, and bringing Python, data science and machine learning to Snowflake, this should become a big revenue driver in the long term.
Then we have Snowflake Cortex, which will allow querying within Snowflake based on natural language. So you won’t necessarily have to write in in SQL anymore, and this will open up the platform for more people i.e. sales, HR, managers, etc. Anyone can have a go then at Snowflake, as opposed to having to email a business analyst to retrieve some data. Additionally, the company will also introduce a Co-Pilot which will further lower the barriers to work and become productive on the platform. So Cortex is really about bringing LLM capabilities to the platform, based on the pdf documents you have stored in Snowflake’s data lake, Cortex will use these to provide an LLM based on your company’s know-how. In addition, Snowflake will be hosting Mistral’s and Meta’s LLM models, so that customers can easily customize them on their own data.
Another new product is Unistore, which will turn Snowflake’s data warehouse into a database as well effectively. It will be optimized for traditional database row operations such as reading, writing, updating and deleting, while providing ACID compliance. This would make the company a competitor to traditional SQL databases such as those from Oracle, Microsoft and IBM, although with unlimited scalability. Google has a similar product called Spanner, and this field of having traditional SQL databases with horizontal scaling is called ‘NewSQL’. Where Oracle still holds the advantage is that it is hyperfast, with speeds of below one millisecond as the software is written in C and running on one server. Whereas Snowflake’s NewSQL database will be running in a cloud datacenter and therefore will be facing network latencies of around 10 milliseconds. However, for by far nearly all applications, a 10 milliseconds latency is sufficient. For comparison, the blink of an eye goes into the hundreds of milliseconds.
A third reason for optimism is that customer optimizations are coming to an end, this is the CFO on the recent call:
“Customer optimizations returned to a normal level, with 8 of our top 10 accounts growing sequentially. History has shown that optimizations expand our long-term opportunity.”
Optimizations are when customers or Snowflake make compute running over the platform more efficient, thereby lowering costs for clients. A simple example would be a client indexing his data better, so that queries run faster. Snowflake has always been happy to assist with this as their view is that the lower the cost for customers, this will lead to more data and workflows on their platform, boosting revenues even in the medium term. The CFO going over this on the call:
“Last year, we saw a 62% increase in the number of jobs running on Snowflake year-over-year, with a corresponding 33% increase in revenue. And that's because we continue to show our customers that we become cheaper and cheaper to them every year. And when we do that, it opens up new workload opportunities for us, and we'll continue to do that.”
Finally, we got some additional indicators on the call that the outlook is improving. This is the CFO again:
“Our international territories returned to meaningful growth, outperforming expectations for the first time in a year.
We signed our largest deal ever in Q4, a 5-year $250 million contract with an existing customer.”
The only real flipside I came across for the thesis that this is a conservative guide, is that on the conference call, the company mentioned several times that a lot of performance enhancements are being rolled out this year. So it could be that they’re expecting this to be a major headwind. The CFO mentioned that these already were a 6.3% revenue headwind last year. So if that would increase to perhaps 10% this year, a company which would normally have been growing at 35%, would print a revenue growth number of only 25% roughly. It could be that this a key reason for their cautious stance. While the revenue growth trajectory has some uncertainty in the near term, in my view there is probably little doubt that the long term growth trajectory should remain solid.
Historically, when growth rates for quality SaaS players disappoints, they usually bounce back afterwards. Good SaaS names have managed to sustain high rates of growth for long periods of time. So weaker quarters typically aren’t anything to get overly concerned about.

The best long term bull case for Snowflake was probably given by Intel’s CEO, who was running virtualization software company VMware previously:
“We are in year 20 of the public cloud, and you have 60%-plus of compute in the cloud, but 80%-plus of data remains on-prem.”
So when investing in the cloud and SaaS space, data remains the area still most ripe for disruption and were companies should be able to sustain high rates of growth into the coming decade and more.
The CEO change
Slootman announced he is retiring which will be fodder for some bears, however, he is 65 now and successfully scaled the company to generate multi-billions in annual revenues. Given his age this certainly seems like an understandable decision, and he is remaining on as Chairman to supervise and advice new CEO Sridhar Ramaswamy.
Ramaswamy joined the company via the Neeva acquisition last year, a startup focused on applying AI to web search and a field which Ramaswamy previously already was active in at Google. At the latter giant, he ran the search ads business and successfully scaled it to above $100 billion in revenues. And after joining Snowflake, he took control of the company’s AI strategy.
So it seems like he has been making a very solid impression on Slootman, as he was already offered the CEO role after having been only one year at the company. As a result, the game plan of Snowflake looks to be now that Slootman has built out the sales organization to grow the business, Ramaswamy’s task is now to make Snowflake into a large player in the data science and AI landscape.
This is the new CEO discussing why he took the job:
“I signed up because I think Snowflake can be a $100 billion revenue company, it's that combination of proven ability to execute at scale plus the technology chops. I took over the YouTube ads business in 2015, nearly quadrupled it to over $20 billion of revenue. Started shopping ads on Google from scratch too, it’s like $25-plus billion today. I had other public company CEO opportunities, other big tech opportunities, so I had a fair number of choice. But Snowflake stood out in terms of technology, a company that has the ability to create enormous value today with the products that we have.”
Financials — share price of $162 on the NYSE at time of writing, ticker ‘SNOW’
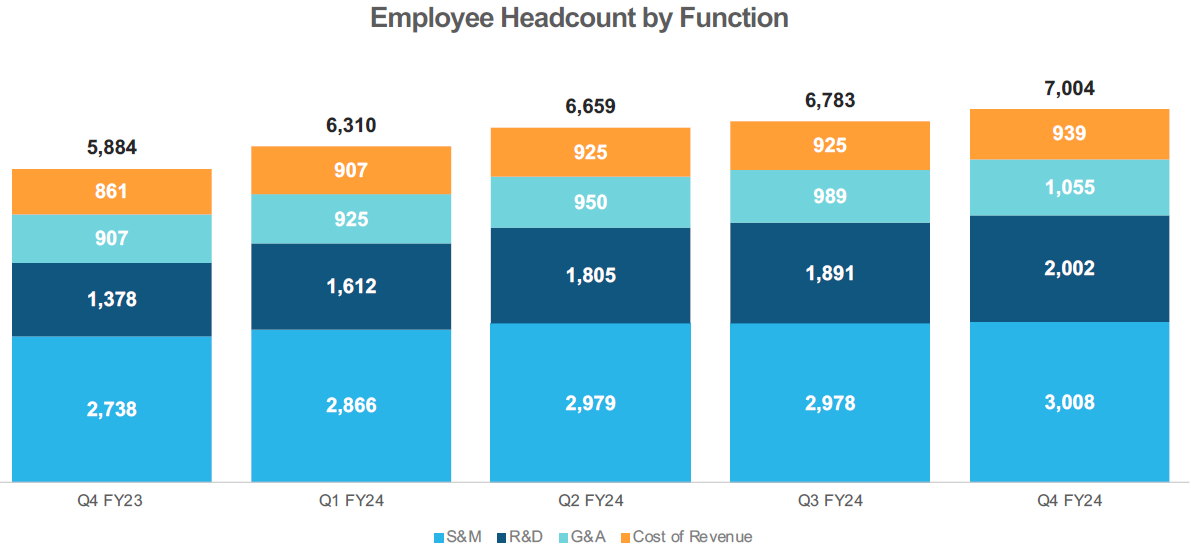
The company has been increasing headcount especially in R&D over the last year, the obvious aim here is to build out their AI capabilities:
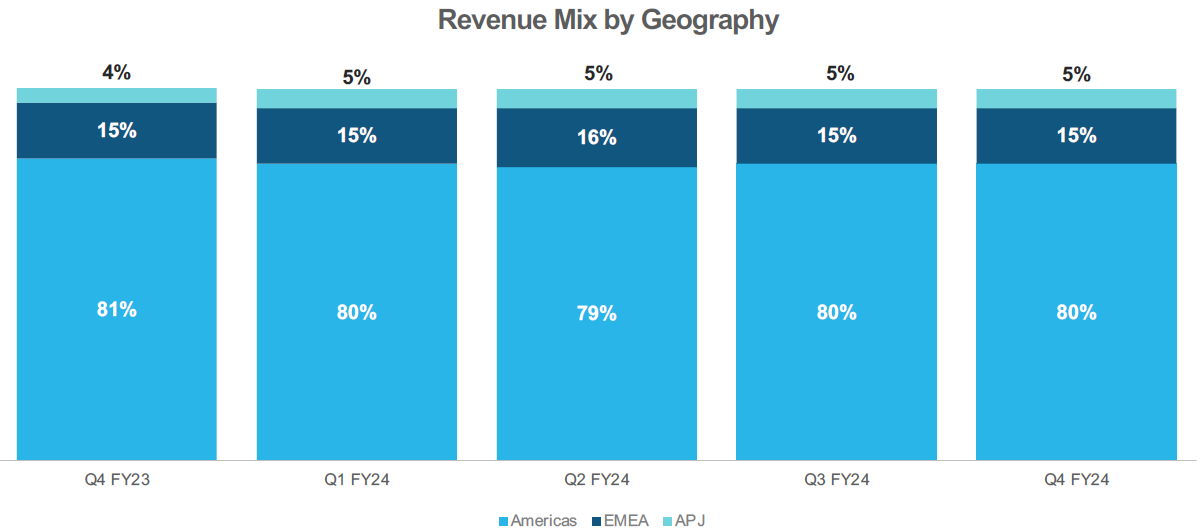
Additionally, Snowflake remains heavily focused towards the US, so long term we should expect a long path for growth in the rest of the world:
As already discussed, the company has been obtaining better pricing from the hyperscalers which was a key reason in Snowflake growing its gross margin:

Wall Street’s estimates below. The modelling probably looks conservative on the top line and especially on the margins. Doubling the top line and margins by ‘27 would give around $4 of EPS, so $1.8 consensus looks very low.

To make a historical comparison on valuation, Slootman’s previous company, ServiceNow, was for a long time wildly underestimated by the market. This company even used to trade at around 7-8x sales eight years ago, when growth rates were far higher. It seems to me that the market has gotten a bit smarter since then and figured out that valuing high-growth quality software companies at above 10x sales still provides good risk-reward.

Given the long runway of growth Snowflake should have ahead, below 15x sales, the risk-reward is looking decent again in this name in my opinion.

If you enjoy research like this, hit the like & restack buttons, and subscribe if you haven’t done so yet. Also, please share a link to this post on social media or with others who might be interested, it will help the publication to grow.
I’m also regularly discussing tech and investments on my Twitter.
Disclaimer - This article is not a recommendation to buy or sell the mentioned securities, it is purely for informational purposes. While I’ve aimed to use accurate and reliable information in writing this, it can not be guaranteed that all information used is of this nature. The views expressed in this article may change over time without giving notice. The future performance of the mentioned securities remains uncertain, with both upside as well as downside scenarios possible.
Great overview
Fantastic research and writing!