

Nvidia, AMD, and the AI cycle
Nvidia, AMD, and the AI cycle
An overview of the datacenter GPU landscape post Q3

The current AI training boom & the coming inferencing market
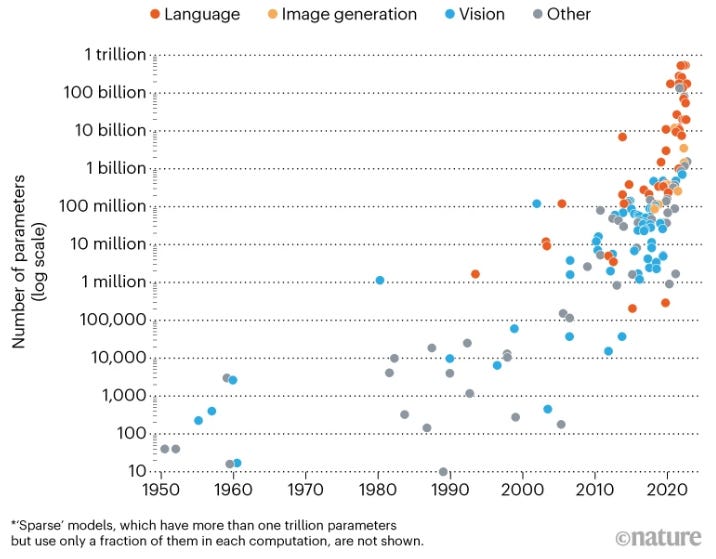
We are currently in the midst of a massive capex boom in AI acceleration. The competitive drive to build the best LLM — which is a function of data size, data quality, model size and computing power — has led to a demand for ever greater GPU computing clusters. For example, looking at model sizes as measured by the number of parameters, even on a log scale, the number of LLM parameters per leading model is currently increasing in an exponential fashion (chart below from Nature). GPT4 is estimated to run on 1.8 trillion parameters, with a training time of over three months on 25,000 Nvidia A100s. Training clusters of 10 to 25 thousand GPUs have become common. We know for example that Tesla is training their FSD system on a cluster of around 10 to 14 thousand GPUs, and Elon Musk purchased a similar amount for his recent AI startup which has now released the first beta version of Grok.
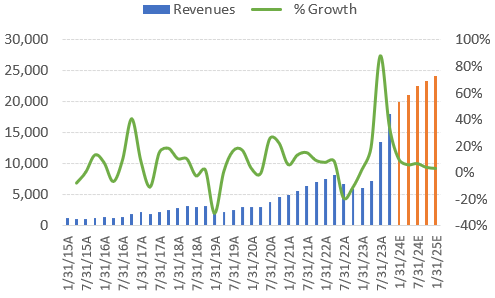
A key question is how long this capex phase will last, infrastructure investments are notoriously cyclical and semiconductors are no exception here. Looking at Nvidia’s recent history, revenues regularly expand for six to eight quarters followed by a cyclical correction where it takes one to two quarters to find a bottom. As you can see on the green line, during those down quarters, revenues tend to drop 20 to 30% quarter on quarter. In this historical context, Wall Street modelling in revenues to continue expanding for another five quarters is no stretch.
During Nvidia’s previous quarter, demand was especially coming from the large cloud and internet giants. This quarter, while demand from this area saw continued sequential growth, we also started seeing a more diversified revenue stream coming from the enterprise and government markets. Nvidia’s CFO explains:
“Consumer internet companies and enterprises drove exceptional sequential growth in Q3, comprising approximately half of our data center revenue and outpacing total growth. Companies like Meta are in full production with deep learning recommender systems and are also investing in generative AI to help advertisers optimize images and text. The enterprise wave of AI adoption is now beginning. Enterprise software companies such as Adobe, Databricks, Snowflake and ServiceNow are adding AI copilots to their platforms. And broader enterprises are developing custom AI for vertical industry applications such as Tesla and autonomous driving. Cloud service providers drove roughly the other half of our data center revenue in the quarter. Demand was strong from all hyperscale CSPs as well as from a broadening set of GPU-specialized CSPs. Nvidia H100 GPU instances are now generally available in virtually every cloud. We have significantly increased supply every quarter this year to meet strong demand and expect to continue to do so next year.”
The last sentence is a crucial one, as the company is guiding here to continue increasing supply into next year. This was later confirmed by Jensen Huang on the call, the UBS analyst asked:
“Do you think that data center can grow even into 2025?”
To which Jensen responded:
“Absolutely, we believe that data center can grow through 2025.”
Nvidia’s CFO added some details here:
“We’ve done a really solid job of ramping every quarter, which has defined our revenue. We are still working on improving our supply and plan on continuing and growing all throughout next year.”
The way I’m reading this is for sequential growth to continue for each quarter next year, obviously this is a very bullish guidance. Now, keep in mind that even for Nvidia it will be hard to see what demand will look like nine to twelve months from now, semi companies usually give a bullish outlook until one morning you wake up and they’re suddenly guiding the next quarter down with 30%. When we get to valuation, we’ll go through how much of this is priced in already.
The key question remains how long the current buildout of accelerated computing will last. I’ve previously estimated that capex plans for AI training might look something like below — a large initial spend in year 1, some replacements and limited expansions in years 2 & 3, and if the project is a success, another large expenditure to update and expand the infrastructure during year 4. This would obviously give very cyclical revenues for Nvidia.
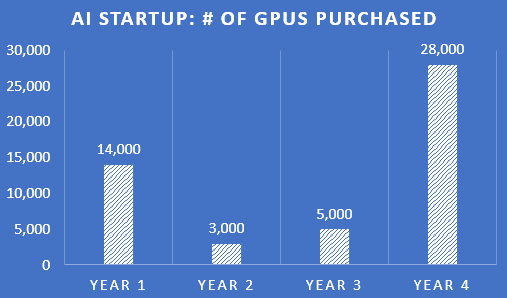
However, inferencing is estimated to be the largest market of the two, and here GPUs will be installed more based on demand, giving more non-cyclical revenues which should grow more in line with the revenues the AI software is generating. Comparing current Nvidia shipments to installed global computing power might give us a hint of how long Nvidia’s revenues could continue growing from here. While 100% penetration levels of accelerated computing seem unlikely at this stage, perhaps it could make sense that around 15% of installed computing power would become accelerated. Clearly there is substantial upside to this number, as LLMs have tremendous potential to increase productivity.
Nvidia’s datacenter business is currently generating revenues at a rate of $68 billion per annum, the number which Jensen is frequently citing is $1 trillion in installed datacenter capacity around the globe. Now, this is somewhat comparing apples and oranges, but anyways, the penetration level on this basis is around 6.8%. Currently what Nvidia is shipping remains limited compared to installed computing power.
Another methodology is comparing the number of datacenter GPUs Nvidia is shipping compared to the number of installed servers, a proxy for installed global computing power, which is around 104 million servers (during Nvidia’s capital markets day, they mentioned 26 million servers currently running in the public cloud and assuming a 25% cloud penetration, we can get to the total servers number estimated). As Nvidia should be shipping datacenter GPUs currently at a rate of around 2.8 million units per annum (and less as the mix towards H100s and H200s increases), this would give a penetration level for accelerated computing of around 2.7%:

Now, both methodologies are imprecise but they give an idea that Nvidia’s current sales remain limited compared to the computing power that is out there. So if LLMs become an important part of daily workloads such as with the rise of copilots, digital assistants, skynet, and generative AI, this gives the potential for Nvidia’s revenues to grow into the coming years as inferencing demand continues to gain track.
So in a nutshell, the bull case is that while revenue growth has already been spectacular with the capex boom in AI training GPUs, we continue to see growth in the coming years as the inferencing market builds out. The bear case on the other hand would be that demand for inferencing disappoints, and we get the usual cyclical correction within 4 to 6 quarters or so. When we get to valuation, we’ll map these scenarios out to have a look what this means for the risk-reward picture in the share price.
Nvidia’s strategy to stay ahead
To stay ahead of competition, Nvidia will both be innovating on the hardware and software sides. Firstly, the company is moving to a one year cadence in releasing new datacenter GPUs. On the timeline below you can see that between the A100 and H100 releases, there was a two year gap. However, now the company will be releasing each year a new flagship architecture, with the B100 in ‘24 and the X100 in ‘25. In between we also get an upgrade of the H100 with more high-bandwidth memory, the H200. A key reason for this cadence acceleration is that AI methodologies are still evolving rapidly, and this allows the company to not only make its chips more powerful, but to also adapt them to new types of workloads.

Nvidia will also be releasing the GH200, a GPU and a powerful ARM-based CPU on the same board. Both the H200 and GH200 are making use of advanced CoWoS packaging, which interconnects chip-dies side by side into one functional module. As this a supply constrained process still, which is the main reason Nvidia hasn’t been able to fulfill GPU demand this year, the company will also be releasing a less powerful GPU not in need of CoWoS, the L40S. This GPU is powerful enough for AI model fine-tuning as well as inferencing. So there should be ample demand. Jensen explained the GH200 during the Q2 call:
“Grace Hopper is in high-volume production now. With all of the design wins that we have in high-performance computing and AI infrastructures, we are on a very fast ramp with our first datacenter CPU to a multibillion dollar product line. Grace Hopper has very fast memory as well as very large memory. In the areas of vector databases or semantic search, what is called retrieval augmented generation (RAG), you could have a generative AI model be able to refer to proprietary data before it generates a response, and that data is quite large and with a context length that is very high. This way, the generative models have the ability to still be able to naturally interact with you on one hand and on the other hand, be able to refer to proprietary data or domain-specific data and reduce hallucination.”
The GH200 consists of one 72 core ARM-based Nvidia CPU (named Grace) and one Nvidia H100 GPU (Hopper). The total memory is huge, 480GB of RAM with another 96GB or 141GB of HBM depending on the version, which gives around 600GB in total of rapidly accessible memory. Communication is happening over NVLink, giving bandwidth of 900GB per second.
The other main reason for this increase in GPU cadence is that Nvidia will be better able to update its software driving these powerful chips. Software updates can give strong performance improvements, of even 20% or more. Ian Buck, the father of CUDA and Nvidia’s current head of accelerated computing, delved into this at the BoA conference:
“The other part of the roadmap is software. It’s easy to look at a benchmark result, see a bar chart, and assume that it is the speed of the hardware. But often underreported are the investments Nvidia is making in the software stack. For inference, you can find even more optimizations than you can do in training because you’re coming out the last mile. For Hopper for example, we’ve just released a new piece of software called TensorRT-LLM. TensorRT is our optimizing compiler for inference. The optimizations we made in that software doubled Hopper’s performance on inference. And that came through a whole bunch of optimizations, for the tensor core it’s using 8-bit floating point and it improved the scheduling and managing of the GPU’s resources.”
Jensen Huang continued on this topic during the Q3 call:
“We could create TensorRT-LLM because CUDA is programmable. If CUDA and our GPUs were not so programmable, it would really be hard for us to improve software stacks at the pace that we do. TensorRT-LLM on the same GPU improves the performance by a factor of two and then on top of that, H200 increases it by another factor of 2. And so our inference performance improved by a factor of 4 within about a year’s time. And so it’s really hard to keep up with. Mostly, the software benefits because of the architecture. And so we want to accelerate our roadmap for that reason.”
We’ve already discussed previously the software landscape in AI and how Nvidia had a decade-plus head start compared to everyone else, thanks to their CUDA computing platform and subsequent integrations into the popular Python/ C++ based training libraries such as Tensorflow and Pytorch. Competitors are slowly but steadily catching up with this. For example, AMD’s competing ROCm platform is now enjoying native support from Pytorch on Linux, but not on Mac or Windows yet. However, Nvidia CUDA is now also being supported by Python’s pandas, which is the key software library for data pre-processing, as well as Apache Spark, which is the dominant library for data streaming. Jensen talked about this on the Q3 call:
“Before you could train a model, you have to curate the data, maybe you have to augment the data with synthetic data, you clean the data and normalize the data. All of that data is measured in terabytes and petabytes. And the amount of data processing that you do before data engineering is quite significant, it could represent 30% to 50% of the amount of work that you ultimately do. We accelerate Spark. We accelerate Python. One of the coolest things that we just did is called cuDF pandas, without one line of code, pandas now is accelerated by Nvidia CUDA just out of the box.”
The final Nvidia advantage is really their capability to integrate all these hardware and software advancements into one full stack, making it easy to roll out AI acceleration capabilities within a datacenter. Nvidia has the GPUs, now also the CPUs, Mellanox (Nvidia’s networking business which includes Infiniband and now also ethernet), and then the countless software packages written making everything easy to use. Jensen discussing this on the Q3 call:
“Nvidia is in every cloud, but everybody’s platform is different and yet we’re integrated into all of their stacks. We work incredibly well with all of them. It includes all of the domain-specific libraries that we create, the reason why every computer company without thinking can integrate Nvidia into their roadmap. The list of domain-specific libraries that we have is incredibly broad. And then finally, now we have an end-to-end solution for data centers: InfiniBand networking, ethernet networking, x86, ARM,.. just about every combination of technology solutions and software stacks provided. But the thing that really holds it together, and this is a great decision that we made decades ago, is everything is architecturally compatible.”
Ian Buck added some further detail, from the BoA conference:
“Certainly, it is possible to take one AI workload and get it working on anyone’s hardware platform. What makes it hard is to make it a platform for continuous optimization and evolution, and to be a platform that can run all the workloads that one would run inside of a data center. With so many people innovating inside of generative AI, they’re innovating here at a click that’s way faster than we’re actually producing new architectures. And one of the benefits about working at Nvidia is, we get to work with all the different AI companies, so we get to optimize those layers of the stack that matter. We can innovate at the hardware layer, at the compiler layer, the system software layer, and the library layer.”
Customers like integrated solutions which work out of the box. For example, currently the vast majority of revenues is being driven by Nvidia’s HGX platform (source: Nvidia’s CFO). This is one of the reasons why Microsoft is able to achieve the same stellar processing power in its datacenters as Nvidia is generating within its own. This holistic approach where everything fits together makes it also very easy to scale current datacenters out, an important requirement as LLMs keep growing in size.
To illustrate this, Nvidia’s HGX platform is a combination of eight H100 GPUs on one baseboard connected over NVLink. 32 of these platforms can be networked together, giving a total of 256 GPUs able to act as one unit. NVLink has 14x the bandwidth of the latest generation of PCIe, able to transfer 900GB per second. A schematic drawing of how one HGX platform operates:
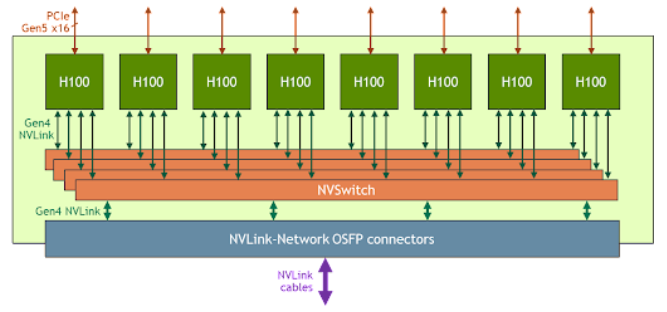
And what it looks like in real life, the board below has six A100 GPUs inserted with two remaining open slots. This is easily inserted into a server to connect to CPUs and networking interface cards (NICs).

In conclusion, Nvidia is not only ahead but is innovating on all fronts. Not even large competitors such as AMD or Intel are able to match this pace of innovation, let alone newcomers in the field. We’ll take a more detailed look at AMD later on, but Nvidia is outspending even this large rival on R&D while the former is also heavily focused on CPUs. This means that Nvidia can focus more of its R&D dollars on GPUs compared to AMD, so the difference will be more stark purely in this area:
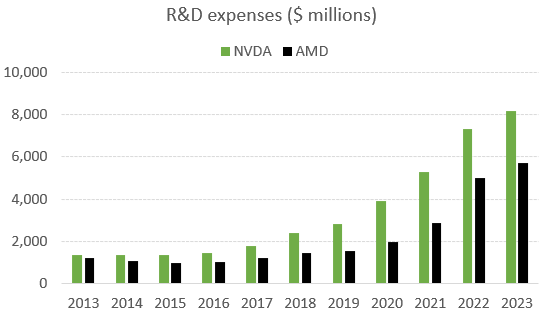
Nvidia’s strengths in the coming inferencing market
Up to now, most of Nvidia’s GPU revenues have been driven by AI training. However, we’re now entering the next phase where the trained large language models are being deployed for inferencing. Nvidia’s CFO detailed this new source of demand:
“Inference is contributing significantly to our data center demand as AI is now in full production for deep learning recommenders, chatbots, copilots and text-to-image generation. And this is just the beginning. Nvidia AI offers the best inference performance and versatility, and thus the lowest cost of ownership. We are also driving a fast cost reduction curve.”
We already discussed the company’s fast innovation curve above. Ian Buck added more details how Nvidia is planning to lead in inferencing as well:
“Training and inference are highly related, in order to train a model, you have to first infer and calculate the error, then apply the error back to the model to make it smarter. So the first step of training is inference and so it is natural that customers are deploying their inference models with their training clusters, with their HGXs. Our inference platform consists of many choices to optimize for TCO, for workload and for performance. In the case of inference, it usually is about datacenter throughput and latency. You have the L40S, which is often used for larger inferencing and fine-tuning tasks. So you can take an existing foundation model and then fine-tune it to do that sort of last-mile specialization for your data workload. By connecting them with NVLink, we can basically turn eight GPUs into one GPU and run the model that much faster to provide real-time latency.”
In order for inferencing to become a large market, we will need a large user base willing to pay for LLM-type assistants or portals. One of the most promising of these are copilots, which are built-in LLMs into software apps which at the command of the user can automate various tasks, speeding up productivity. For example, LLMs can generate new software code, create a new slidedeck based on provided information, or create a variety of excel formulas and operations. This makes advanced software usage available to a wider set of employees as you can now interact based on text as opposed to having to formulate a SQL query for example, which is obviously not for everyone. As another example, you could have an LLM built into Google Maps which highlights the best places to visit during a city trip while also booking you a suitable hotel and dinner spot. The smaller of these copilots can run on your device while larger ones will run in the cloud. So besides the large, foundational models such as OpenAI’s GPT4 and Google’s Gemini, companies will be offering smaller, customized copilots for their apps.
Nvidia has been aiming for years to move further into software so it should be no surprise that they’ve built a service here to customize AI models. AI foundry is a cloud platform where customers can customize foundational models provided by Nvidia. This is very similar to Amazon Bedrock. The CFO discussed this on the Q3 call:
“At last week’s Microsoft Ignite, we deepened and expanded our collaboration with Microsoft across the entire stack. We introduced an AI foundry service for the development and tuning of custom generative AI applications running on Azure. Customers can bring their domain knowledge and proprietary data, and we help them build their AI models using our AI expertise and software stack in our DGX Cloud. SAP and Amdocs are the first customers on Microsoft Azure.”
Jensen provided some further details: “Our monetization model is that, each one of our partners, they rent a sandbox on DGX Cloud where we work together. We help them build their custom AI. Then that customer AI becomes theirs and they deploy it on a runtime that runs across, everything Nvidia. We have a giant installed base in the cloud, on-premise, anywhere. And we call that Nvidia AI Enterprise. Our business model is basically a software license. Our customers then can build their monetization model on top of.”
So Nvidia has built a whole hardware and software stack optimized for AI acceleration and clients can leverage this platform to run their customized AI on top. This should make a lot sense. Nvidia does seem to have strong capabilities in AI model building as well, as Mercedes and other prominent automotive manufacturers are now leveraging the company’s platform for self-driving software. And Mercedes has given Nvidia in return even a 50% revenue share on their self-driving business.
Ian Buck gave his views on what’s next in LLMs:
“One of the reasons why GPT is so large, it’s trained on the corpus of human understanding. So when you ask about the capacity and how this is going to grow over time, there’s not going to be one model to rule them all. There will be a large diversity of different models based upon the innovations that are going to continue down this space, and also specialization across all of these fields. Large language models don’t have to be just the language of humans, it could be the language of biology, physics, or material science. We’re seeing specialty, regional GPU datacenters popping up everywhere. We’ve gone from being a corner of the datacenter into what datacenters are now being designed for.”
The above makes me think that Nvidia should be in a strong position in the inferencing market as well, although I’m expecting some key competitors here to be able to take some share, something they’ve been struggling with so far in AI training. So Nvidia’s market share in this area shouldn’t be as dominant as their 80% share in AI training, but they should be in a good position still to take a large share of the market.
AMD and Intel are still far behind
AMD has really been playing catch-up, they were far behind on both the software side as well as on the hardware side, illustrated by the facts that they haven’t been competing in the MLPerf benchmarking tests, and haven’t been getting any orders.. Intel has been competing on MLPerf, but usually gets slaughtered by the superiority of Nvidia’s hardware. The results of a test earlier this year are shown below. Note that Intel didn’t compete on four of the eight tests, illustrating the versatility of Nvidia’s GPUs, which are able to generate top results on each type of AI workload.

However, more recently Intel competed again on the GPT3 test, and they narrowed their underperformance. From Forbes:
“By Intel’s math, adding support for FP8 doubled the previous performance of the Habana Gaudi 2, landing it at about 50% of the per-node results of Nvidia’s H100. Intel claimed that this equates to superior price performance, which we verified with channel checks, which said that the Gaudi 2 performs quite well and is much more affordable and available than Nvidia. These results should help pave the way for Gaudi 3, due in 2024. But of course, at that time, Intel will have to compete with Nvidia’s next-generation GPU, the B100, aka Blackwell.”
Intel showcasing their results on four of the eight tests:

So Intel achieving better price performance on GPT3 is an interesting result, however, it remains questionable to what extent this leads to order growth. Intel mentioned on their Q3 call that their pipeline doubled, but this will be from an extremely low base. Somewhat better, AMD guided to do $2 billion of revenues with their new MI300 GPU next year, but this is almost a drop in the bucket compared to the $56 billion per annum Nvidia is currently generating in datacenter GPUs. However, UBS at their tech conference mentioned that AMD is currently getting orders at 10% of what Nvidia is getting. Such a share would be quite attractive for AMD, but currently they have an advantage on HBM and bandwidth with their MI300 which is now starting shipments. Nvidia will be releasing two GPUs over the coming twelve months which will likely shrink AMD’s share again.
AMD’s MI300 will likely mostly be used for inferencing workloads and Lisa Su alluded to this as well on the conference call: “We’re very pleased with the inference performance on MI300, especially for large language model inference given some of our memory bandwidth and memory capacity. We think that’s going to be a significant workload for us.”
Clearly the shares of both these competitors are still small compared to Nvidia and I suspect this will remain to be the case for the coming two to three years. Long term, as Intel and AMD keep building out their software stack and are able to build better and more versatile hardware, there should be room to take a more significant share in the datacenter GPU market. Perhaps what they really need is the pace of innovation into AI to slow down, as currently Nvidia seems to be the only one really able to build proper hardware to run the latest models on. A fast pace of innovation in AI is really to Nvidia’s advantage, as they both have the stack and scale to move fast and to keep up with the AI industry.
Hyperscalers’ custom silicon to become a more credible competitor over the long run
Hyperscalers are offering custom silicon solutions to meet customers’ AI needs. Widely known is that Google has the TPU, although this one is mostly still used for the company’s internal workloads; Amazon offers Trainium and Inferentia, and Microsoft recently announced Maia. Typically the hyperscalers will also offer compilers so that you can run your Pytorch code on their chips. To the extent that this silicon is currently in use, it is mostly for inferencing workloads. Nvidia’s GPUs remain in short supply and so these are currently being allocated towards training, with inferencing being ran on the silicon that’s available. Both Tencent and Baidu for example made comments along these lines on their recent calls, where they were looking at domestic silicon to run their inferencing on while keeping their Nvidias for all the training.
Naturally the hyperscalers have deep pockets and they should be able to go on a decent innovation cadence as well. Amazon will be releasing both Trainium 2 and Inferentia 3 next year for example. However, note that Google has been releasing a new TPU every two years or so and is currently on its fifth generation already, while their ability to compete with Nvidia has remained limited.
Note that Amazon recently cited some AI wins on the latest call for their chips: “As most people know, there’s a real shortage right now in the industry in chips, it’s really hard to get the amount of GPUs that everybody wants. And so it’s just another reason why Trainium and Inferentia are so attractive to people. They have better price performance characteristics than the other options out there, but also the fact that you can get access to them. And so you’re seeing very large LLM providers make big bets on those chips. I think Anthropic deciding to train their future LLM model on Trainium and using Inferentia as well is really a statement. And then you look at the really hot start-up Perplexity.ai, who also just made a decision to do all their training and inference on top of Trainium and Inferentia. So those are 2 examples.”
However, Dylan Patel’s SemiAnalysis notes that Amazon is using these chips as a loss leader: “It should be noted that Amazon is buying and deploying far more of their Trainium and Inferentia 2 chips despite them being inferior to Microsoft’s Maia. This is because Amazon has relatively lower allocations of Nvidia GPUs and also because Amazon believes in subsidizing their own parts to get the external ecosystem going. Contrast this with Microsoft whose AI accelerators are primarily for internal workloads, because they actually have a strong AI services and API business. This means Microsoft will pick the best TCO chip rather than subsidize a loss leader likeAmazon.” The same article mentions that Microsoft’s orders for the Maia 100 are quite low compared to their AMD and Nvidia orders.
So currently we have a situation where competitors for Nvidia are emerging, but the fast pace in AI innovation is to Nvidia’s advantage — it’s much harder for competitors to chase down a fast moving target. Nvidia has the scale, talent and stack to quickly innovate and optimize for the latest innovations in AI. The public cloud is dominated by three mammoths — Amazon, Microsoft and Google — which can leverage their strong position to promote their custom silicon on their respective clouds, for example by attractive pricing as noted by SemiAnalysis above. This means that over the long run they could pose more serious competition for Nvidia, especially when the pace of innovation in AI slows down. However, a fast pace of innovation could well last decades. Take the science of physics for example, where Einstein’s miracle year in 1905 kicked off a fast pace of discovery which lasted into the 1960s.
Nvidia’s China problem could be mitigated
The US government introduced more stringent export controls into China as well as into the Middle East last quarter. Nvidia’s CFO discussing the impact: “Our sales to China and other affected destinations derived from products that are now subject to licensing requirements have consistently contributed approximately 20 to 25 percent of datacenter revenues over the past few quarters. We expect that our sales to these destinations will decline significantly in the fourth quarter, though we believe they’ll be more than offset by strong growth in other regions. We are working to expand our datacenter product portfolio to offer compliant solutions for each regulatory category, including products for which the US government does not wish to have advanced notice before each shipment. These products, they may become available in the next coming months. However, we don’t expect their contribution to be meaningful as a percentage of revenues in Q4.”
Naturally this a blow to Nvidia, however, the regulatory document mentions that if you can monitor what the chips are being used for with cryptography (making sure it are non-military applications), you could still get a license to ship the chip. Naturally this could mitigate a big part of the blow as most applications should be non-military and it would provide a nice compromise between the US government and the semi industry.
My personal belief is that it is more advantageous for the US to keep China reliant on its technology. It not only gives you a lot of leverage, but you maintain the capital flows into the US economy which can be further used to strengthen your tech position. China is now building up reasonably advanced technology such as SMIC’s 7nm fab with a potential to move to 5nm, which the talented Chinese semi-designers from companies such as Huawei can leverage to develop their GPUs. Without these sanctions, the Chinese AI scene would have been fully reliant on Nvidia’s GPUs for the foreseeable future. Now, China will be very driven in building up their domestic GPU champions.
The natural counter argument is that without EUV, the Chinese won’t be able to go beyond 5nm, while the Western-aligned players such as TSMC, Samsung and Intel are moving to 2nm and beyond in the near future. Thus, with Western access to EUV and soon high-NA EUV, the technological gap between the Allies and China will widen.
Now, this is all very logical, however, a drawback to this strategy could be that a China that is not technologically reliant on the US anymore and which has secured domestic supply chains for still reasonably advanced technology could be more likely to go to war to achieve its regional interests, such as the annexation of Taiwan as well as other islands such as the Senkakus for example.
Financials Nvidia, share price of $468 at time of writing, ticker NVDA on the NASDAQ
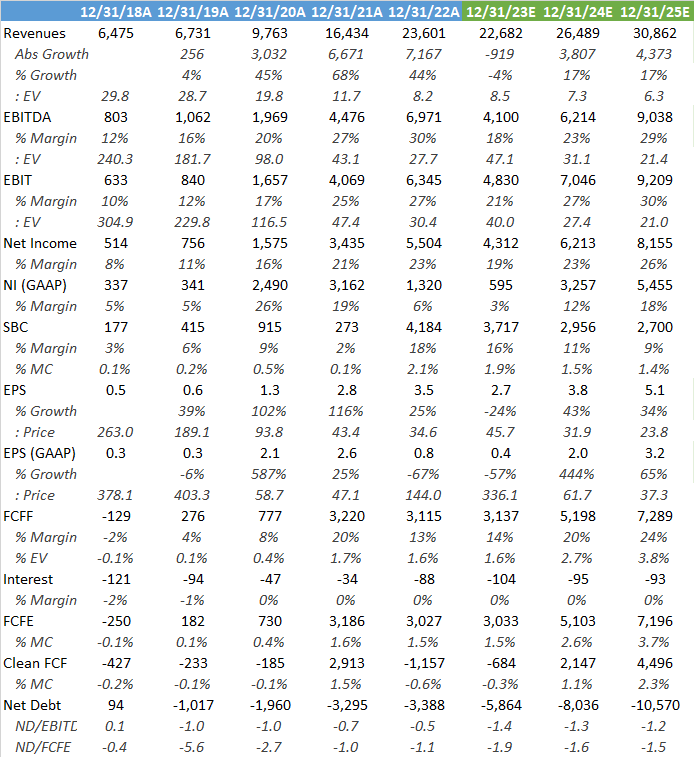
So obviously Nvidia’s datacenter revenues have exploded and management is guiding for these to continue growing into next year.
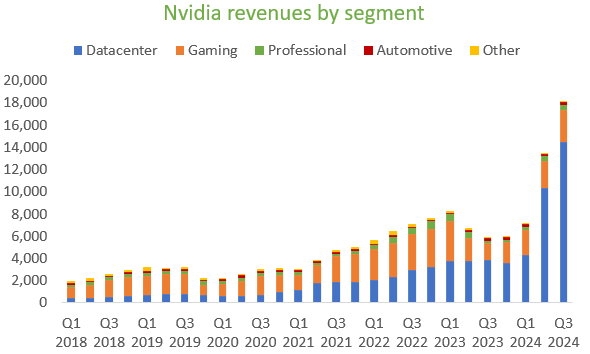
Wall Street is modelling in continuous growth for Nvidia, taking a bull case view on the inferencing market. If these estimates turn out to be right, Nvidia is currently a very cheap stock. For example, putting the sell side’s fiscal year ‘26 projected EPS on a 30x PE next-twelve-months, investors can make an attractive 46% IRR (annualized return) in this stock, giving a share price of around $710 at the start of calendar year ‘25.
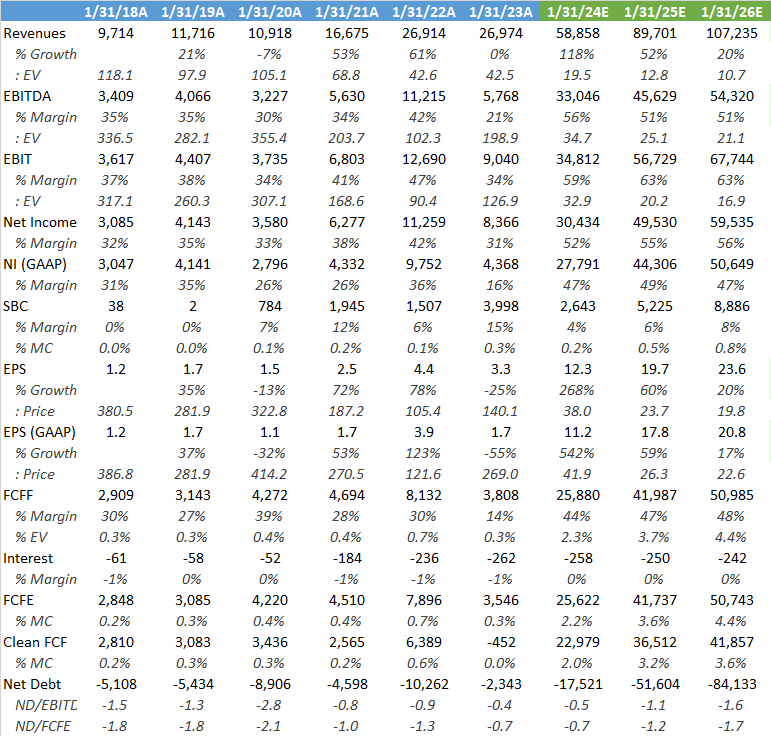
The market however is sceptical on these numbers, reckoning Nvidia in the coming year is heading towards a peak-of-the-cycle EPS number with a cyclical correction coming thereafter. This can be witnessed in Nvidia currently trading on its lowest multiple in three years. After all, if the market would be buying the sell side’s numbers, this stock would be trading on 65x, not on 24x as it is now:
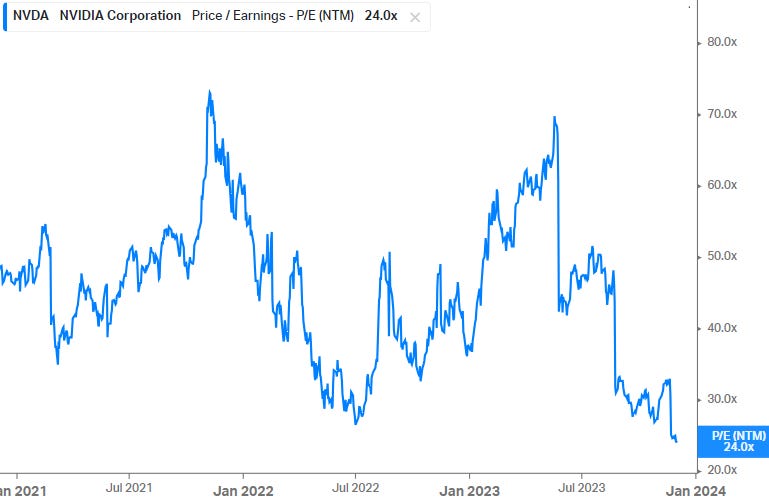
Historically Nvidia’s quarterly EPS has seen sharp pullbacks after periods of expansion. During the last cyclical low for example, quarterly EPS reached around $0.26 per quarter. However, I do believe that the LLM breakthrough in AI will permanently change the demand picture for datacenter GPUs, and that therefore a pullback to those kinds of levels is unlikely. Worst case, hopefully, if we fall back to around $0.75 to $1 of quarterly EPS levels, this would give around $3.5 bottom-of-the-cycle annual EPS. However, under such a scenario the stock price would see PE expansion as the market will look ahead and start anticipating a cyclical recovery. If the market would price the stock then on a 60x PE, the share price could fall back to $210.
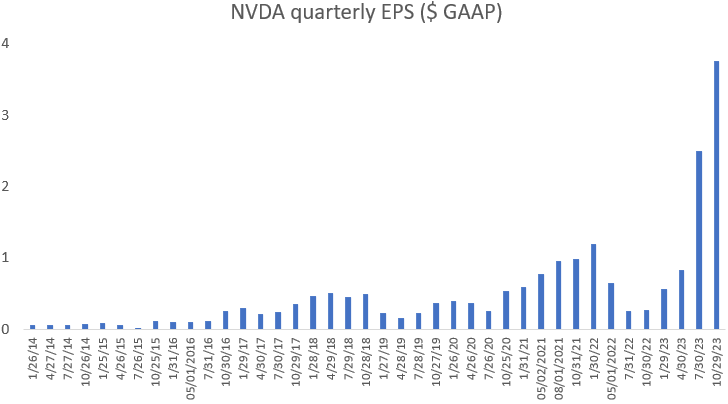
So we’ve stress-tested this stock and gone both through the bull and bear case scenarios. Overall, I’m currently leaning more towards a bull case but it will depend how bullish you are on AI. If you think LLMs will become prevalent in daily workloads around the globe, the stock is probably a buy. Whereas if you think a sharp cyclical correction in GPU demand will start 4 to 6 quarters from now, you could be looking into put options for example.
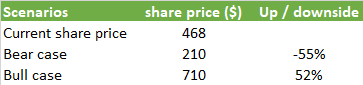
Financials AMD, share price of $121 at time of writing, ticker AMD on the NASDAQ
AMD has become a diversified semiconductor powerhouse, providing datacenter CPUs and GPUs, PC CPUs and GPUs, GPUs for gaming consoles, and FPGAs with its Xilinx acquisition:
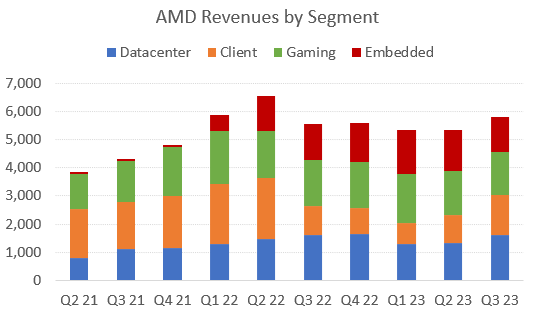
The sell side is only modelling in $3.8 billion revenue growth for ‘24, so if UBS is right that AMD is currently getting datacenter GPU orders at a rate of 10% of Nvidia, revenues from this area could bring in $5 to $6 billion. This should make the shares a good performer. However, note that AMD is an expensive name, trading at 62x ‘24 GAAP PE for example.
That said, valuation is still in line with its five year average:
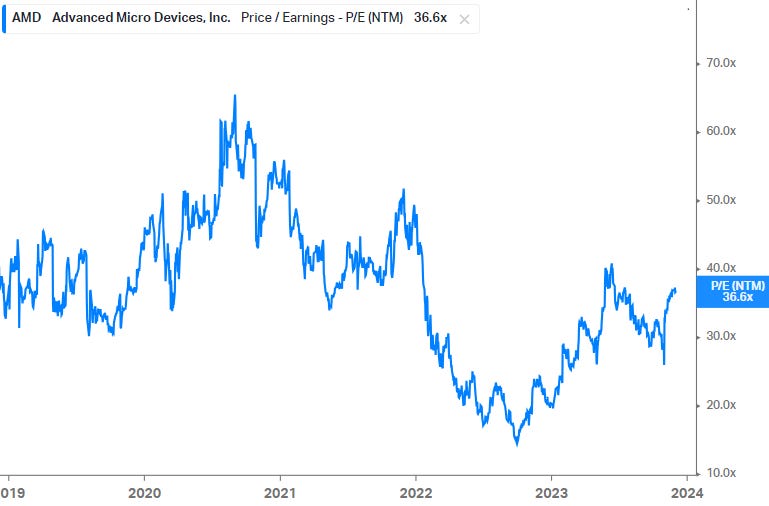
Overall, AMD would be an interesting name to hold as well for those bullish on AI. Note that the company also has an attractive FPGA portfolio which is seeing application in inferencing as well. Going into the second half of this decade, the company should also become more competitive with Nvidia as it builds out its full stack, including software solutions as well as a better hardware cadence.
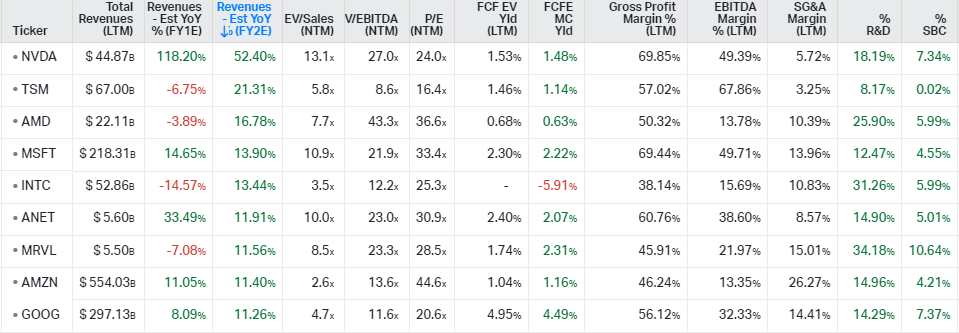
An overview of the financial metrics among both companies’ peers. Nvidia is clearly the name where the sell side is estimating the highest top line growth rates:
If you enjoy research like this, hit the like button and subscribe. Also, please share a link to this post on social media or with colleagues with a positive comment, it will help the publication to grow. All shares are appreciated.
I’m also regularly discussing tech and investments on my Twitter.
Disclaimer - This article is not a recommendation to buy or sell the mentioned securities, it is purely for informational purposes. While I’ve aimed to use accurate and reliable information in writing this, it can not be guaranteed that all information used is of this nature. The views expressed in this article may change over time without giving notice. The future performance of the mentioned securities remains uncertain, with both upside as well as downside scenarios possible. Before investing, I recommend speaking to a financial advisor who can take into account your personal risk profile.
This is a great deep dive, thanks for sharing
The BofA Securities analyst covering NVDA has commented on <10% of data centers being accelerated. I’ll see if I can’t find the note from last year and send it over to you. All that to say though, it fits your narrative as well at <10%.